在这些公司提问
设计动态消息应用程序是一个经典的系统设计问题,但几乎没有现有资源详细讨论如何设计动态消息的前端。
问题
设计一个动态消息应用程序,其中包含用户可以与之交互的 feed 帖子列表。
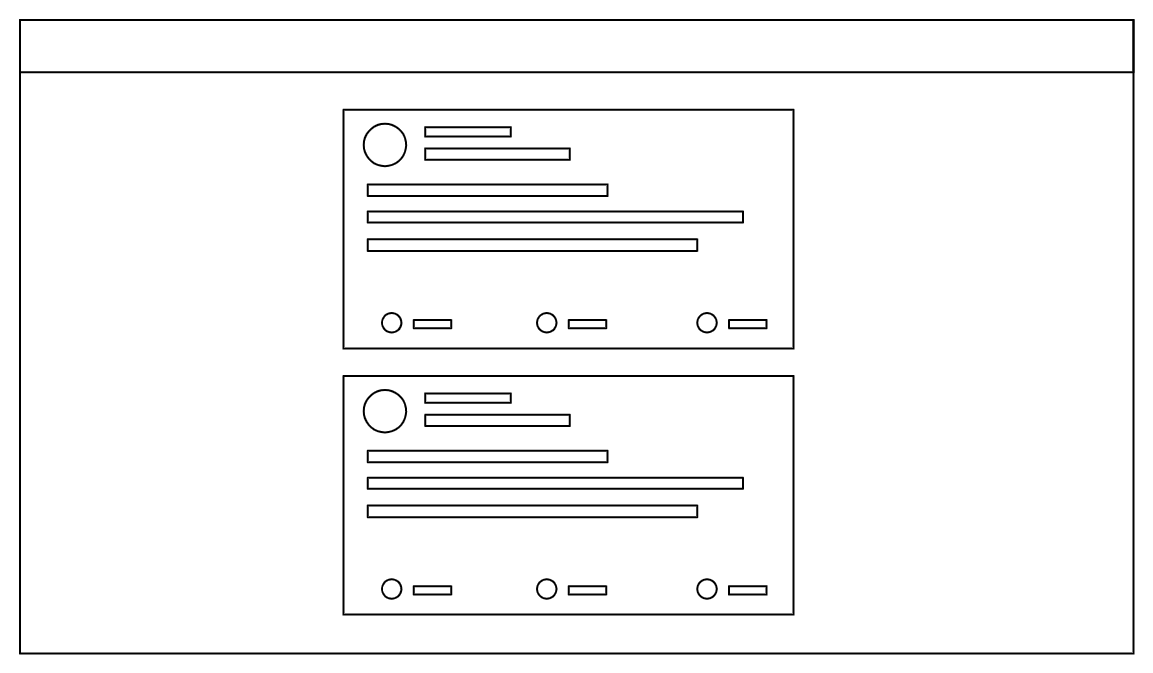
真实案例
需求探索
要支持哪些核心功能?
- 浏览包含用户及其朋友帖子的新闻 Feed。
- 喜欢和回应 Feed 帖子。
- 创建和发布新帖子。
评论和分享将在下面进一步讨论,但未包含在核心范围内。
支持哪些类型的帖子?
主要是基于文本和图像的帖子。 如果时间允许,我们可以讨论更多类型的帖子。
Feed 应该使用什么分页 UX?
无限滚动,这意味着当用户到达 Feed 末尾时,将添加更多帖子。
该应用程序是否会在移动设备上使用?
不是优先事项,但良好的移动体验会很好。
架构/高级设计
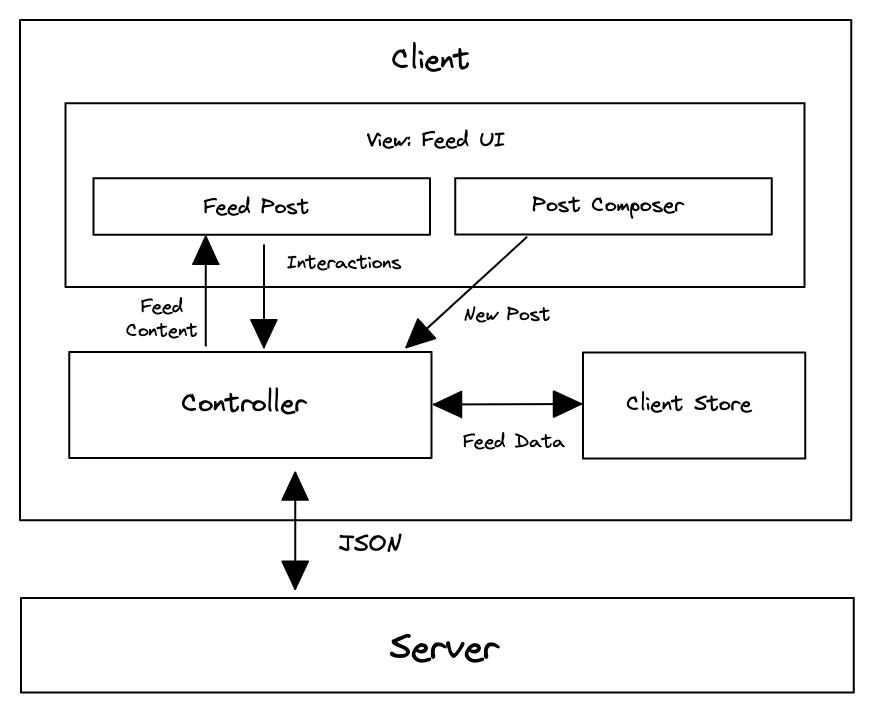
组件职责
- 服务器:提供 HTTP API 以获取 Feed 帖子和创建新的 Feed 帖子。
- 控制器:控制应用程序内的数据流并向服务器发出网络请求。
- 客户端存储:存储整个应用程序所需的数据。 在新闻 Feed 的上下文中,存储中的大多数数据将是 Feed UI 所需的服务器生成的数据。
- Feed UI:包含 Feed 帖子列表和用于撰写新帖子的 UI。
- Feed 帖子:呈现 Feed 帖子的数据,并包含用于与帖子交互的按钮(喜欢/回应/分享)。
- 帖子撰写器:WYSIWYG(所见即所得)编辑器,供用户创建新的 Feed 帖子。
渲染方法
传统的 Web 应用程序在何处呈现内容方面有多种选择,无论是在服务器端还是客户端呈现。
- 服务器端渲染 (SSR):在服务器端渲染 HTML,这是最传统的方式。最适合需要 SEO 且不需要大量用户交互的静态内容。 博客、文档站点、电子商务网站等网站都是使用 SSR 构建的。
- 客户端渲染 (CSR):在浏览器中呈现,通过使用 JavaScript 将 DOM 元素动态添加到页面中。最适合交互式内容。 仪表板、聊天应用程序等应用程序是使用 CSR 构建的。
有趣的是,新闻 feed 应用程序介于两者之间,既有大量静态内容,又需要交互。 实际上,Facebook 使用了一种混合方法,它提供了两全其美的效果:使用 SSR 快速初始加载,然后对页面进行水合以附加用于用户交互的事件侦听器。 后续内容(例如,当用户到达 feed 末尾时添加的更多帖子)和页面导航将使用 CSR。
现代 UI JavaScript 框架(如 React 和 Vue)以及元框架(如 Next.js 和 Nuxt)支持此渲染策略。
阅读有关 在 Web 上渲染 和 "为新的 Facebook.com 重建我们的技术堆栈" 博客文章 的更多信息。
数据模型
新闻 feed 显示从服务器获取的帖子列表,因此此应用程序中涉及的大部分数据将是服务器生成的数据。 唯一需要的客户端数据是帖子撰写器中输入字段的表单状态。
| 实体 | 来源 | 属于 | 字段 |
|---|---|---|---|
Feed | 服务器 | Feed UI | posts ( Post 列表), pagination (分页元数据) |
Post | 服务器 | Feed 帖子 | id, created_time, content, author (一个 User), reactions, image_url (对于包含图像的帖子) |
User | 服务器 | 客户端存储 | id, name, profile_photo_url |
NewPost | 用户输入 (客户端) | 帖子撰写器 UI | message, image |
尽管 Post 和 Feed 实体分别属于 feed 帖子和 feed UI,但所有服务器生成的数据都可以存储在客户端存储中,并由需要它们的组件查询。
客户端存储的形状在这里并不特别重要,只要它采用可以从组件轻松检索的格式即可。 从第二页获取的新帖子应与之前的帖子合并到一个列表中,并更新分页参数 (cursor)。
高级:规范化存储
Facebook 和 Twitter 都使用规范化的客户端存储。 如果术语“规范化”对您来说是新的,请阅读 Redux 关于规范化状态形状的文档。 简而言之,规范化数据存储:
- 类似于数据库,其中每种类型的数据都存储在自己的表中。
- 每个项目都有一个唯一的 ID。
- 跨数据类型的引用使用 ID(如外键),而不是嵌套对象。
Facebook 使用 Relay(由于了解 GraphQL 模式,可以规范化数据),而 Twitter 使用 Redux,如 "剖析 Twitter 的 Redux 存储" 博客文章 所示。
拥有规范化存储的好处是:
- 减少重复数据:同一数据片段的单一事实来源,可以在 UI 上的多个实例中呈现。 例如,如果许多帖子是由同一作者撰写的,我们将在客户端存储中存储
author字段的重复数据。 - 轻松更新同一实体的所有数据:在 feed 帖子包含用户撰写的许多帖子并且该用户更改其姓名的情况下,能够立即在 UI 中反映更新的作者姓名会很好。 使用规范化存储比仅存储服务器响应原文的存储更容易做到这一点。
在面试的背景下,我们实际上不需要为新闻 feed 使用规范化存储,因为:
- 除了用户/作者字段外,没有太多重复数据。
- 新闻 feed 主要用于消费信息,没有太多更新数据的用例。 Feed 用户交互(例如点赞)仅影响 feed 帖子中的数据。
因此,使用规范化存储的优势是有限的。 实际上,Facebook 和 Twitter 网站包含许多其他功能,这些功能将受益于规范化存储提供的功能。
延伸阅读:让 Instagram.com 速度更快:第 3 部分 — 缓存优先
接口定义 (API)
| 来源 | 目的地 | API 类型 | 功能 |
|---|---|---|---|
| 服务器 | 控制器 | HTTP | 获取 feed 帖子 |
| 控制器 | 服务器 | HTTP | 创建新帖子 |
| 控制器 | Feed UI | JavaScript | 传递 feed 帖子数据,反应 |
| 帖子撰写器 | 控制器 | JavaScript | 传递新帖子数据 |
最有趣的 API 莫过于讨论获取 feed 帖子列表的 HTTP API,因为分页方法值得讨论。从服务器获取 feed 帖子的 HTTP API 具有基本细节:
| 字段 | 值 |
|---|---|
| HTTP 方法 | GET |
| 路径 | /feed |
| 描述 | 获取用户的 feed 结果。 |
有两种常见的方式来返回分页内容,每种方式都有其自身的优缺点。
- 基于偏移的分页
- 基于游标的分页
基于偏移的分页
基于偏移的分页涉及使用偏移量来指定从哪里开始检索数据,并使用限制来指定要检索的项目的数量。这就像说,“从第 10 条记录开始,给我接下来的 5 个项目”。偏移量可以是一个显式数字,也可以从请求的页码转换而来。请求第 3 页,页面大小为 5,将转换为偏移量 10,因为在第 3 页之前有 2 页,2 x 5 = 10。对于基于偏移的分页 API 来说,更常见的是接受 page 参数,并且服务器将在查询数据库时将其转换为 offset 值。
基于偏移的分页 API 接受以下参数:
| 参数 | 类型 | 描述 |
|---|---|---|
size | number | 每页的项目数 |
page | number | 要获取的页码 |
给定 feed 中有 20 个项目,参数 {size: 5, page: 2} 将返回项目 6 - 10 以及分页元数据:
{"pagination": {"size": 5,"page": 2,"total_pages": 4,"total": 20},"results": [{"id": "123","author": {"id": "456","name": "John Doe"},"content": "Hello world","image": "https://www.example.com/feed-images.jpg","reactions": {"likes": 20,"haha": 15},"created_time": 1620639583}]}
这里省略了其余结果项,但如果代码块标注为 json,示例本身应该保持为合法 JSON。
并且底层的 SQL 查询类似于:
SELECT * FROM posts LIMIT 5 OFFSET 0; -- 第一页SELECT * FROM posts LIMIT 5 OFFSET 5; -- 第二页
基于偏移的分页具有以下优点:
- 用户可以直接跳转到特定页面。
- 易于查看总页数。
- 易于在后端实现。 SQL 查询的
OFFSET值使用(page - 1) * size计算。 - 易于与各种数据库系统一起使用,并且不依赖于特定的数据存储机制
但是,基于偏移的分页存在一些问题:
不准确的页面结果:对于经常更新的数据,当前页面窗口在一段时间后可能不准确。想象一下,用户已经获取了 feed 中的前 5 个帖子。一段时间后,又添加了 5 个帖子。如果用户滚动到 feed 的底部并获取第 2 页,将获取原始第 1 页中的相同帖子,并且用户将看到重复的帖子。
// 初始帖子(最新的在左边,最旧的在右边)帖子:A、B、C、D、E、F、G、H、I、J^^^^^^^^^^^^^ 第 1 页包含 A - E// 随着时间的推移添加的新帖子帖子:K、L、M、N、O、A、B、C、D、E、F、G、H、I、J^^^^^^^^^^^^^ 第 2 页也包含 A - E
客户端可以尝试变得智能,通过不显示已经可见的帖子来去重。然而,这需要自定义逻辑,并且客户端将不得不发出新的请求以弥补缺少的新帖子,这会产生额外的网络往返。对于项目数量会随着时间减少的用例,页面最终可能会丢失一些项目。
页面大小无法轻易更改:基于偏移量的分页的另一个缺点是,客户端无法更改后续查询的页面大小,因为偏移量是页面大小和所请求页面的乘积。
| 页面 | 页面大小 | 结果 |
|---|---|---|
| 1 | 5 | 项目 1 - 5 |
| 2 | 5 | 项目 6 - 10 |
| 2 | 7 | 项目 8 - 14 |
在上面的例子中,如果客户端从{page: 1, size: 5}变为{page: 2, size: 7},它将错过项目 6 和 7。
查询性能随时间推移而下降:最后,查询性能会随着表格变大而下降。对于巨大的偏移量(例如OFFSET 1000000),数据库仍然必须读取多达count + offset行,丢弃offset行,并且仅返回count行,这会导致大型偏移量的查询性能非常差。这被认为是后端知识,但了解它很有用,并且您可能会因为提及它而获得奖励。
基于偏移量的分页在 Web 应用程序中很常见,用于显示搜索结果等列表,其中需要跳转到特定页面,并且结果不会更新得太快。因此,博客、旅游预订网站、电子商务网站将受益于使用基于偏移量的分页来获取其搜索结果。
基于游标的分页
基于游标的分页使用指针(游标)指向数据集中的特定记录。它不是说“给我项目 11 到 15”,而是说“给我从 [特定项目] 开始的 5 个项目”。
游标通常是唯一标识符,可以是项目 ID、时间戳或其他内容。后续请求使用最后一个项目的标识符作为游标来获取下一组项目。在 SQL 中,一个例子是:
SELECT * FROM table WHERE id > cursor LIMIT 5.
基于游标的分页 API 接受以下参数:
| 参数 | 类型 | 描述 |
|---|---|---|
size | number | 每页的结果数 |
cursor | string | 最后一个获取项目的标识符。数据库查询将使用此标识符。 |
{"pagination": {"size": 10,"next_cursor": "=dXNlcjpVMEc5V0ZYTlo"},"results": [{"id": "123","author": {"id": "456","name": "John Doe"},"content": "Hello world","image": "https://www.example.com/feed-images.jpg","reactions": {"likes": 20,"haha": 15},"created_time": 1620639583}]}
同样,这里为了简洁只展示一个结果项。
基于游标的分页的优点:
- 在大型数据集上更高效、更快。
- 避免了不准确的页面窗口问题,因为随着时间的推移添加的新帖子不会影响偏移量,偏移量由固定的游标确定。非常适合实时数据。
Facebook、Slack、Zendesk 使用基于游标的分页来获取其开发者 API。
基于游标的分页的缺点:
- 由于客户端不知道游标,因此无法在不浏览前几页的情况下跳转到特定页面。
- 与基于偏移量的分页相比,实现起来稍微复杂一些。
为了使后端实现基于游标的分页,数据库需要将游标唯一地映射到一行,这可以使用数据库表的主键或在某些情况下使用时间戳来完成。
为新闻提要使用哪种分页?
简而言之,基于偏移量的分页和基于游标的分页之间的选择很大程度上取决于数据和需求。基于偏移量的方式更简单,更适合静态或小型数据集,其中直接访问页面很重要。基于游标的方式对于大型、动态数据集更有效、更可靠,其中数据序列很重要并且经常变化。
对于无限滚动的动态消息流,其中:
- 新帖子可以经常添加到 feed 的顶部。
- 新获取的帖子会附加到 feed 的末尾。
- 表格大小增长很快。
基于游标的分页显然更胜一筹,应该用于新闻 feed。
创建帖子
此 HTTP 方法供用户创建新帖子,该帖子将显示在他们自己的 feed 以及他们是朋友的其他人的 feed 中。
| 字段 | 值 |
|---|---|
| HTTP 方法 | POST |
| 路径 | /posts |
| 描述 | 创建一个新帖子。 |
| 参数 | { body: '...', media: '...' } |
HTTP API 的参数将取决于所制作的帖子类型。在大多数情况下,这在面试中不是一个关键的讨论点。
响应格式可以是单个帖子,也可以是 feed 中最新帖子的列表。如果返回单个帖子,一个更适合前端写入规范化 store 的做法是返回规范化后的 payload,也就是 canonical Post 记录以及它引用到的 User 和 Media 实体:
{"post": {"id": "124","authorId": "456","body": { "text": "Hello world", "entities": [] },"mediaIds": ["m_1"],"engagementSummary": {"reactions": { "like": 20, "haha": 15 },"totalReactions": 35,"commentCount": 0,"shareCount": 0},"viewerReaction": null,"viewerHasShared": false,"createdAt": 1620639583},"users": [{ "id": "456", "name": "John Doe" }],"media": [{"id": "m_1","src": "https://www.example.com/feed-images.jpg","alt": "An image alt","width": 1200,"height": 800}]}
给定此新帖子数据,客户端 store 需要先把引用到的用户和媒体实体合并到各自的 collection,再把新的 post ID 插入 feed 列表的开头。
优化和深入研究
由于新闻 feed 应用程序中有几个部分,因此一次专注于一个部分并查看可以对特定部分进行的优化会更有条理:
一般优化
这些优化适用于页面的每个部分。
对 JavaScript 进行代码拆分以提高性能
随着应用程序的增长,页面和功能的数量会增加,这将导致需要运行应用程序的 JavaScript 和 CSS 代码更多。代码拆分是一种将页面上所需代码拆分为单独文件的技术,以便可以并行或在需要时加载它们。
通常,代码拆分可以在两个级别上完成:
- 在页面级别拆分:每个页面将仅加载该页面所需的 JavaScript 和 CSS。
- 在页面内延迟加载资源:仅在需要时或在初始渲染后加载非关键资源,例如仅在页面下方需要或仅在交互时使用的代码(例如模态框、对话框)。
对于新闻 feed 应用程序,只有一个页面,因此页面级别的代码拆分不太相关,但是懒加载对于其他目的仍然非常有用。懒加载在 feed 帖子部分有更详细的讨论,因为它与 feed 帖子 UI 最相关。
作为参考,Facebook 将其 JavaScript 加载分为 3 个层级:
- Tier 1: 显示高于折叠内容所需的基本布局,包括用于初始加载状态的 UI 骨架。
- Tier 2: 完全渲染所有高于折叠内容所需的 JavaScript。在 Tier 2 之后,屏幕上不应再有任何内容因代码加载而发生视觉变化。
- Tier 3: 仅在显示后才需要的资源,这些资源不影响屏幕上的当前像素,包括日志记录代码和用于实时更新数据的订阅。
来源:“为新的 Facebook.com 重建我们的技术堆栈”博客文章
键盘快捷键
Facebook 有许多特定于新闻 feed 的快捷方式,可帮助用户在帖子之间导航并执行常见操作,非常方便!通过在 facebook.com 上点击“Shift + ?”键来亲自尝试。
错误状态
如果任何网络请求失败,或者没有网络连接,请清楚地显示错误状态。
Feed 列表优化
Feed 列表指的是包含 Feed 帖子项目的容器元素。
无限滚动
当用户滚动到当前已加载 feed 的末尾时,无限滚动 feed 会通过获取下一组帖子来工作。这会导致用户看到一个加载指示器和一个短暂的延迟,用户必须等待获取和显示新帖子。
减少或完全消除等待时间的一种方法是在用户到达页面底部之前加载下一组 feed 帖子,这样用户就永远不必看到任何加载指示器。
对于大多数情况,大约一个视口高度的触发距离就足够了。理想的距离足够短,以避免出现误报和浪费带宽,但也足够宽,可以在用户滚动到页面底部之前加载其余内容。可以根据网络连接速度和用户浏览 feed 的速度来计算动态距离。
有两种常用的方法来实现无限滚动。两者都涉及在 feed 底部呈现一个标记元素:
- 监听
scroll事件:将scroll事件侦听器(最好是受限的)添加到页面或计时器(通过setInterval),该计时器检查标记元素的位置是否在距页面底部的某个阈值内。可以使用Element.getBoundingClientRect获取标记元素的位置。 - Intersection Observer API:使用 Intersection Observer API 来监视标记元素何时进入或退出另一个元素或与另一个元素相交,或相交量发生指定的变化。
Intersection Observer API 是一个浏览器原生 API,优于 Element.getBoundingClientRect()。
Intersection Observer API 允许代码注册一个回调函数,只要它们希望监视的元素进入或退出另一个元素(或视口),或者两个元素相交的量发生请求的变化时,就会执行该函数。这样,站点不再需要在主线程上执行任何操作来监视这种元素相交,并且浏览器可以自由地根据需要优化相交的管理。
来源:Intersection Observer API | MDN
虚拟列表
使用无限滚动时,所有已加载的 feed 项目都在一个页面上。当用户向下滚动页面时,更多帖子会附加到 DOM 中,并且 feed 帖子具有复杂的 DOM 结构(需要渲染大量细节),DOM 大小会迅速增加。由于社交媒体网站是长期运行的应用程序(特别是如果单页应用程序),并且 feed 项目列表很容易快速增长,因此 feed 项目的数量可能会导致 DOM 大小、渲染和浏览器内存使用方面的性能问题。
虚拟列表是一种仅渲染视口内帖子的技术。在实践中,Facebook 会把离屏 feed 帖子的真实内容替换成占位用的 spacer <div>,并用动态计算的内联高度(例如 style="height: 300px")保留滚动位置,从而把沉重的子树移出 DOM。这将提高渲染性能,具体表现在:
- 虚拟 DOM 对账(React 特有):由于帖子现在是一个更简单的空版本,React(Facebook 用于渲染 feed 的 UI 库)更容易区分虚拟 DOM 与真实 DOM,以确定必须进行哪些 DOM 更新。
Facebook 和 Twitter 网站都使用虚拟列表。
加载指示器
对于滚动速度非常快的用户,即使浏览器在用户到达页面底部之前就开始请求下一组帖子,该请求可能尚未返回,并且应显示加载指示器以反映请求状态。
与其显示微调器,不如使用 shimmer 加载效果(类似于帖子的内容)会更好。这看起来更美观,也可以用于减少新帖子加载后的布局抖动。
Facebook feed 加载 shimmer 的示例:
动态加载计数
如上所述,在“界面”部分中,基于游标的分页更适合新闻 feed。基于游标的分页的一个好处是客户端可以更改在后续调用中要获取的条目数。我们可以通过根据浏览器视口高度自定义要加载的帖子数来利用这一点。
如果首次 feed 请求是在 CSR 流程里由客户端发起的,应用可以在请求前读取 window.innerHeight,从而更准确地决定首屏要取多少条数据。如果初始 feed 响应是在服务器上生成的,服务器在响应前并不知道视口高度,因此通常会在首个响应里稍微多取一些。后续分页请求则可以根据已经测量到的视口高度动态调整。
在重新挂载时保留 feed 滚动位置
如果用户导航到另一个页面并返回到 feed,则应保留 feed 滚动位置。如果 feed 列表数据与滚动位置一起缓存在客户端存储中,则可以在单页应用程序中实现此目的。当用户返回到 feed 页面时,由于数据已在客户端上,因此可以从客户端存储中读取 feed 列表,并立即在屏幕上显示之前的滚动位置;不需要服务器往返。
过时的 feed
用户将新闻 feed 应用程序作为浏览器选项卡打开而不刷新的情况并不少见。如果上次获取的时间戳超过几个小时,则最好提示用户刷新或重新获取 feed,因为可能存在新帖子,并且已加载的 feed 被视为过时。当重新获取新 feed 时,可以从内存中完全删除当前 feed 以释放内存空间。
另一种方法是自动将新的 feed 帖子附加到 feed 的顶部,但这可能不是期望的,并且必须格外小心,以免影响滚动位置。
截至撰写本文时,如果选项卡已打开一段时间,Facebook 会强制刷新 feed 并滚动到顶部。
Feed 帖子优化
帖子是指包含帖子详细信息的单个帖子元素:作者、时间戳、内容、点赞/评论按钮。
仅在需要时提供数据驱动的依赖项
新闻 feed 帖子可以有许多不同的格式(文本、图像、视频、轮询等),并且每个帖子都需要自定义渲染代码。 实际上,Facebook feed 支持 50 多种不同的帖子格式!
在客户端支持所有帖子格式的一种方法是让客户端预先加载所有可能格式的组件 JavaScript 代码,以便可以渲染任何类型的 feed 帖子格式。但是,并非所有用户的 feed 都会包含所有帖子格式,并且很可能有很多未使用的 JavaScript。由于 feed 帖子格式种类繁多,预先加载所有 JavaScript 代码肯定会导致性能问题。
如果我们只能根据接收到的数据延迟加载组件就好了! 当然可以,但朴素做法往往是在拿到数据、知道帖子类型后,再触发一次额外的模块发现和加载流程。
Facebook 使用基于 JavaScript 的 GraphQL 客户端 Relay 从服务器获取数据。Relay 将 React 组件与 GraphQL 结合起来,允许 React 组件准确声明需要哪些数据字段,并通过 GraphQL 获取这些字段。Relay 还有一个叫做 数据驱动依赖 的能力,通过 @match 和 @module 指令,GraphQL payload 可以携带“当前数据应该匹配哪个渲染模块”的元数据,客户端再按需动态加载对应模块。这样就不需要在首屏预先打包所有帖子类型的渲染代码。
# 演示数据驱动依赖的示例 GraphQL 查询。... on Post {content @match {...TextPostFragment @module(name: "TextComponent.react")...ImagePostFragment @module(name: "ImageComponent.react")}}
上面的查询表示 content 字段会根据返回的数据类型选择不同的渲染分支,每个分支再通过 @module(name: ...) 声明对应的组件模块。服务端返回匹配分支的数据以及模块元数据,客户端随后只动态加载实际需要的那个渲染模块。
来源:重建我们的技术堆栈以适应新的 Facebook.com
渲染提及/主题标签
您可能已经注意到,feed 帖子中的文本内容不仅仅是纯文本。 对于社交媒体应用程序,通常会看到提及和主题标签。
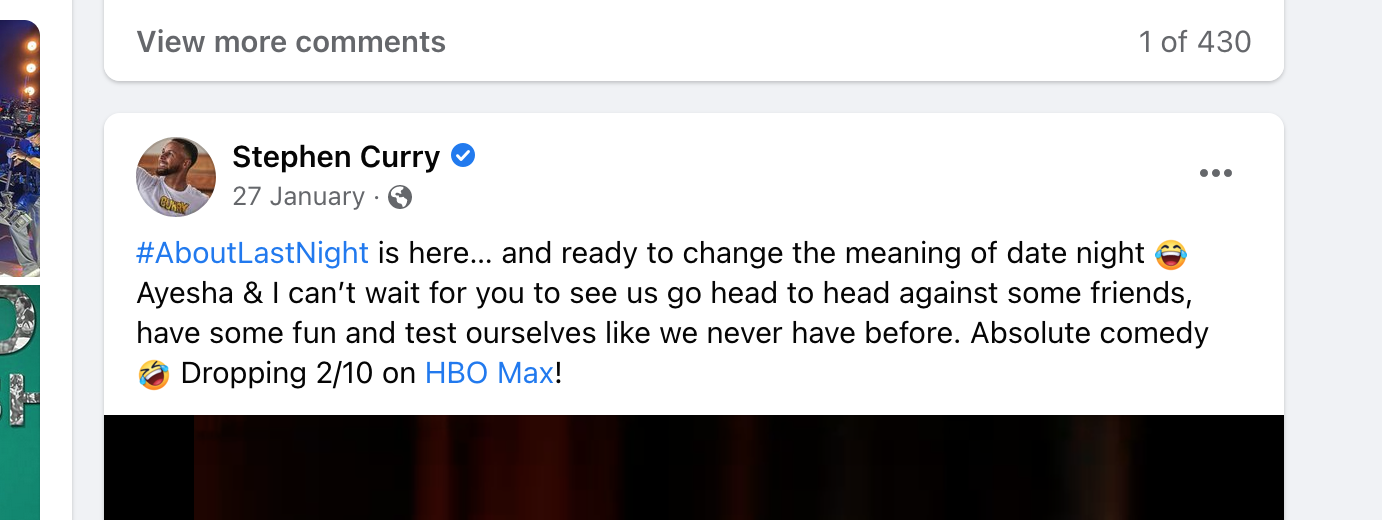
在 Stephen Curry 的上述帖子中,请注意他使用了“#AboutLastNight”主题标签并提到了“HBO Max”Facebook 页面。 他的帖子消息必须以特殊格式存储,以便它包含有关这些标签和提及的元数据。
消息应该采用什么格式才能存储有关提及/主题标签的数据? 让我们讨论可能的格式及其优缺点。
HTML 格式:最简单的格式是 HTML,您可以按照您希望显示的方式存储消息。
<a href="...">#AboutLastNight</a> is here... and ready to change the meaning of date night...Absolute comedy 🤣 Dropping 2/10 on <a href="...">HBO Max</a>!
存储为 HTML 通常是不好的,因为它有可能导致跨站点脚本 (XSS) 漏洞。 此外,在大多数情况下,最好将消息的元数据与显示分离,也许将来您想在渲染之前修饰提及/主题标签,并想将类名添加到链接中。 HTML 格式也使得 API 在非 Web 客户端(例如 iOS/Android)上的可重用性降低。
自定义语法:可以使用自定义语法来捕获有关主题标签和提及的元数据。
- 主题标签:主题标签实际上不需要特殊的语法,以“#”开头的单词可以被视为主题标签。
- 提及:像
[[#1234: HBO Max]]这样的语法足以捕获实体 ID 和要显示的文本。 仅存储实体 ID 是不够的,因为像 Facebook 这样的网站允许用户自定义提及中的文本。
在渲染消息之前,可以使用正则表达式解析字符串以获取主题标签和提及,并将其替换为自定义样式的链接。 如果您不希望将来支持新的富文本实体,则自定义语法是一种轻量级的解决方案,它足够强大。
富文本编辑器格式:Draft.js 是 Meta 推出的一种富文本编辑器框架。它常见的序列化格式之一是 RawDraftContentState,也就是把内容表示成 blocks 加 entityMap。Meta 后来又发布了 Lexical,它是另一种富文本编辑器框架。具体序列化格式会因编辑器而异,但 Draft.js 的 raw format 很适合作为结构化富文本格式的例子。
Draft.js 只是富文本格式的一个例子,可选方案还有很多。使用这类结构化编辑器格式的好处是,不需要自己维护复杂的解析器,并且以后更容易扩展到更多富文本实体类型。不过,这类格式通常会比自定义轻量语法更冗长,也会带来更大的网络 payload 和存储成本。
以下示例说明了如何在 Draft.js 的 raw format 中表示上述帖子。
const draftContent = {blocks: [{key: '9vgd7',text: '#AboutLastNight is here... and ready to change ... Dropping 2/10 on HBO Max!',type: 'unstyled',depth: 0,inlineStyleRanges: [],entityRanges: [{ offset: 0, length: 15, key: 0 },{ offset: 68, length: 7, key: 1 },],data: {},},],entityMap: {0: {type: 'HASHTAG',mutability: 'IMMUTABLE',data: { tag: 'AboutLastNight' },},1: {type: 'MENTION',mutability: 'IMMUTABLE',data: { id: 1234, name: 'HBO Max' },},},};
渲染图片
由于 feed 帖子中可能包含图像,我们还可以简要讨论一些图像优化技术:
- 内容分发网络 (CDN):使用 (CDN) 来托管和提供图像,以实现更快的加载性能。
- 现代图像格式:使用现代图像格式,例如 WebP,它提供卓越的无损和有损图像压缩。
<img>应该使用适当的alt文本- Facebook 通过使用机器学习和计算机视觉来处理图像并生成描述,从而为用户上传的图像提供
alt文本。 - 生成式 AI 模型如今在这方面也做得很好。
- Facebook 通过使用机器学习和计算机视觉来处理图像并生成描述,从而为用户上传的图像提供
- 基于设备屏幕属性的图像加载
- 在 feed 列表请求中发送浏览器尺寸,以便服务器可以决定返回什么图像大小。
- 如果有图像处理(调整大小)功能,请使用
srcset加载最适合当前视口的图像文件。
- 基于网络速度的自适应图像加载
- 互联网连接良好/在 WiFi 上运行的设备:预取尚未进入视口但即将进入视口的屏幕外图像。
- 互联网连接较差:渲染低分辨率的占位符图像,并要求用户明确单击它们以加载高分辨率图像。
懒加载初始渲染不需要的代码
初始渲染不需要与 feed 帖子进行许多交互:
- 反应弹出窗口。
- 由右上角省略号图标按钮显示的下拉菜单,该按钮通常用于隐藏其他操作。
这些组件的代码可以在以下情况下下载:
- 浏览器作为较低优先级的任务处于空闲状态。
- 根据需要,当用户将鼠标悬停在按钮上或单击它们时。
根据 Facebook 以上的层级定义,这些被认为是第 3 层依赖项。
乐观更新
乐观更新是一种性能技术,客户端在用户交互后立即反映更新后的状态,该交互会命中服务器,并乐观地假设服务器请求成功,对于大多数请求都应该如此。这使用户可以获得即时反馈并提高感知性能。如果服务器请求失败,我们可以恢复 UI 更改并显示错误消息。
对于新闻 feed,乐观更新可以通过立即显示用户的反应和更新的反应总数来应用于反应交互。
乐观更新是现代查询库(如 Relay、SWR 和 React Query)内置的一个强大功能。
时间戳渲染
由于一些问题,时间戳渲染是一个值得讨论的话题:多语言时间戳和过时的相对时间戳。
多语言时间戳:像 Facebook 和 Twitter 这样在全球流行的网站必须确保其 UI 适用于不同的语言。有几种方法可以支持多语言时间戳:
- 服务器返回原始时间戳:服务器返回原始时间戳,客户端以用户的语言呈现。这种方法很灵活,但需要客户端包含不同语言的语法规则和翻译字符串,这可能导致大量的 JavaScript 大小,具体取决于支持的语言数量,
- 服务器返回翻译后的时间戳:这需要在服务器上进行处理,但您不必将各种语言的时间戳格式化规则发送给客户端。但是,由于翻译是在服务器上完成的,因此客户端无法在客户端操作时间戳。
IntlAPI:现代浏览器可以利用Intl.DateTimeFormat()和Intl.RelativeTimeFormat()将原始时间戳转换为所需格式的翻译日期时间字符串。
const date = new Date(Date.UTC(2021, 11, 20, 3, 23, 16, 738));console.log(new Intl.DateTimeFormat('zh-CN', {dateStyle: 'full',timeStyle: 'long',}).format(date),); // 2021年12月20日星期一 GMT+8 11:23:16console.log(new Intl.RelativeTimeFormat('zh-CN', {numeric: 'always',style: 'long',}).format(-1, 'day'),); // 1天前
相对时间戳可能会过时:如果时间戳使用相对格式显示(例如,3 分钟前、1 小时前、2 周前等),最近的时间戳很容易过时,尤其是在用户不刷新页面的应用程序中。如果时间戳是最近的(不到一小时),则可以使用计时器不断更新时间戳,以便正确反映任何已过去的重要时间。
图标渲染
帖子操作按钮(如点赞、评论、分享等)中需要图标。 有几种渲染图标的方法:
| 方法 | 优点 | 缺点 |
|---|---|---|
| 分开的图片 | 易于实现。 | 每个图像需要多个下载请求。 |
| 精灵图 | 一个 HTTP 请求下载所有图标图像。 | 设置复杂。 |
| 图标字体 | 可扩展且清晰。 | 需要下载整个字体。 加载字体时出现未样式化的内容。 |
| SVG | 可扩展且清晰。 可缓存。 | 下载文件时闪烁。 每个图像需要一个下载请求。 |
| 内联 SVG | 可扩展且清晰。 | 无法缓存。 |
Facebook 和 Twitter 使用内联 SVG,这似乎也是当今的趋势。 这种技术并非特定于新闻提要,它与几乎每个 Web 应用程序都相关。
来源:“为新的 Facebook.com 重建我们的技术堆栈”博客文章
帖子截断
截断消息内容超长的帖子,并在“查看更多”按钮后面显示其余内容。
对于活动量大的帖子(例如,许多点赞、反应、分享),适当地缩写计数,而不是渲染原始计数,以便于阅读,并且仍然充分传达数量级:
- 好:John、Mary 和其他 103K 人
- 坏:John、Mary 和其他 103,312 人
此摘要行可以在服务器或客户端上构建。 在服务器上与客户端上执行的优缺点与时间戳渲染的优缺点类似。 但是,如果用户列表很大,则绝对不应发送整个用户列表,因为它可能不需要或无用。
Feed 评论
如果时间允许,我们可以讨论如何构建 Feed 评论。 总的来说,同样的规则也适用于评论渲染和评论草稿:
- 基于游标的分页,用于获取评论列表。
- 草拟和编辑评论可以以类似于草拟/编辑帖子的方式完成。
- 在评论输入中延迟加载表情符号/贴纸选择器。
- 乐观更新
- 通过将用户的新评论附加到现有的评论列表中,立即反映新评论。
- 立即显示新的反应和更新的反应计数。
实时评论更新
Facebook Feed 评论的实时更新通过提供新评论和更新的反应计数的实时可见性来增强用户参与度和互动。 这营造了一个动态和响应迅速的沟通环境,鼓励用户积极参与正在进行的对话,而无需手动刷新。 实时更新的即时性有助于提高用户保留率。
在客户端上实现实时更新的常用方法包括:
- 短轮询:短轮询是一种技术,客户端以固定的间隔重复向服务器发送请求以检查更新。 每次请求后连接都会关闭,服务器会立即响应当前状态或任何可用的更新。 虽然短轮询易于实现,但与下面提到的更高级的技术相比,它可能会导致更高的网络流量和服务器负载。
- 长轮询:长轮询通过保持连接打开直到有新数据可用,从而扩展了短轮询的想法。 虽然实现起来更简单,但与其他方法相比,它可能会引入延迟并增加服务器负载。
- 服务器发送事件 (SSE):SSE 是一种标准 Web 技术,它使服务器能够通过单个 HTTP 连接将更新推送到 Web 客户端。 这是一个简单有效的实时更新机制,特别适用于服务器启动更新的场景。
- WebSockets:WebSockets 通过单个、长连接提供全双工通信通道。 这种双向通信允许服务器和客户端随时互相发送消息。 WebSockets 适用于需要低延迟和高交互性的应用程序。
在实践中,生产系统往往还会在 WebSocket 之上再封装一层应用协议,而不是直接发送裸事件。对前端来说,关键点还是订阅管理、背压控制,以及基于可见性来关闭离屏帖子的高频更新。
虽然显示实时更新很棒,但获取 Feed 中已消失的帖子的更新效率不高。 客户端可以根据帖子是否可见来订阅/取消订阅帖子的更新,这减轻了服务器基础设施的负载。
此外,并非所有帖子都应一视同仁。拥有众多关注者(例如,名人和政治家)的用户的帖子将被更多人看到,因此更有可能收到更新。对于此类帖子,新的评论和反应将被频繁添加/更新,获取每个新帖子或反应是不明智的,因为更新频率对于用户来说太高,无法阅读每个新评论。因此,对于此类帖子,可以对实时更新进行去抖动/节流。超过某个阈值后,仅获取更新的评论和反应计数就足够了。
Feed composer 优化
标签和提及的富文本
在撰写帖子时,拥有一个类似结果的 WYSIWYG 编辑体验,其中包含标签和提及,会很好。但是,<input> 和 <textarea> 仅允许输入和显示纯文本。contenteditable 属性将元素转换为可编辑的富文本编辑器。
在这里亲自尝试一下:
可编辑和可格式化 文本,感谢
contenteditable。您甚至可以格式化文本(例如,使用 Ctrl/Cmd + B 加粗)。
但是,在生产中使用 contenteditable="true" 并不是一个好主意,因为它 存在许多问题。最好使用经过实战检验的富文本编辑器库。
Meta 构建过富文本编辑器,例如 Draft.js(已弃用)和 Lexical。其他流行的开源替代方案包括 TipTap 和 Slate。
来源:Facebook 开源富文本编辑器框架 Draft.js
延迟加载依赖项
与渲染新闻 feed 帖子一样,用户可以以许多不同的格式起草帖子,这需要每种格式的专用渲染代码。可以使用惰性加载来按需加载所需格式和可选功能的资源。
可以按需进行惰性加载的代码的非关键功能:
- 图像上传器
- GIF 选择器
- 表情符号选择器
- 贴纸选择器
- 背景图片
可访问性
以下是新闻 feed 的一些可访问性注意事项。
Feed 列表
- 将
role="feed"添加到 feed HTML 元素。
Feed 帖子
- 将
role="article"添加到每个 feed 帖子 HTML 元素。 aria-labelledby="<id>",其中包含 feed 作者名称的 HTML 标签具有该id属性。- feed 帖子中的内容应可通过键盘聚焦(添加
tabindex="0")和适当的aria-role。
Feed 交互
- 在 Facebook 网站上,用户可以通过将鼠标悬停在“赞”按钮上来获得更多反应选项。为了允许键盘用户使用相同的功能,Facebook 显示了一个仅在聚焦时出现的按钮,并且可以通过该按钮打开反应菜单。
- 仅限图标的按钮如果没有附带标签,则应具有
aria-label(例如 Twitter)。
参考资料
- 为新的 Facebook.com 重建我们的技术栈
- 让 Facebook.com 尽可能多的人可以使用
- 我们如何构建 Twitter Lite
- 构建新的 Twitter.com
- 剖析 Twitter 的 Redux 存储
- Twitter Lite 和大规模高性能 React 渐进式 Web 应用程序
- 让 Instagram.com 速度更快:第 1 部分
- 让 Instagram.com 速度更快:第 2 部分
- 让 Instagram.com 速度更快:第 3 部分 — 缓存优先
- 在 Slack 上演进 API 分页
更新日志
- 2024/08/21
- 为有效负载响应添加了更多
image字段的属性 - 提到了
Intl.RelativeTimeFormatAPI
- 为有效负载响应添加了更多
- 2023/12/04
- 增加了关于实时评论的部分