Autocomplete
Asked at these companies
Autocomplete is a common question asked by many companies and encompasses many useful front end concepts and techniques which can be generalized to other front end system design questions. It is highly recommended to study this question well and thoroughly!
Question
Design an autocomplete UI component that allows users to enter a search term into a text box, a list of search results appear in a popup and the user can select a result.
Some real-life examples where you might have seen this component in action:
- Google's search bar on google.com where you see a list of primarily text-based suggestions.
- Facebook's search input where you see a list of rich results. The results can be friends, celebrities, groups, pages, etc.
A back end API is provided which will return a list of results based on the search query.
Requirements
- The component is generic enough to be usable by different websites.
- The input field UI and search results UI should be customizable.
Requirements exploration
These are questions you should be asking your interviewer to dive deeper into the problem and refine the requirements.
What kind of results should be supported?
Text, image, media (image accompanied with text) are the most common type of results but we cannot anticipate all the different kinds of results that users of the component will want to render.
What devices will this component be used on?
All possible devices: laptop, tablets, mobile, etc.
Do we need to support fuzzy search?
Not for the initial version. We can explore this if we have time.
Architecture
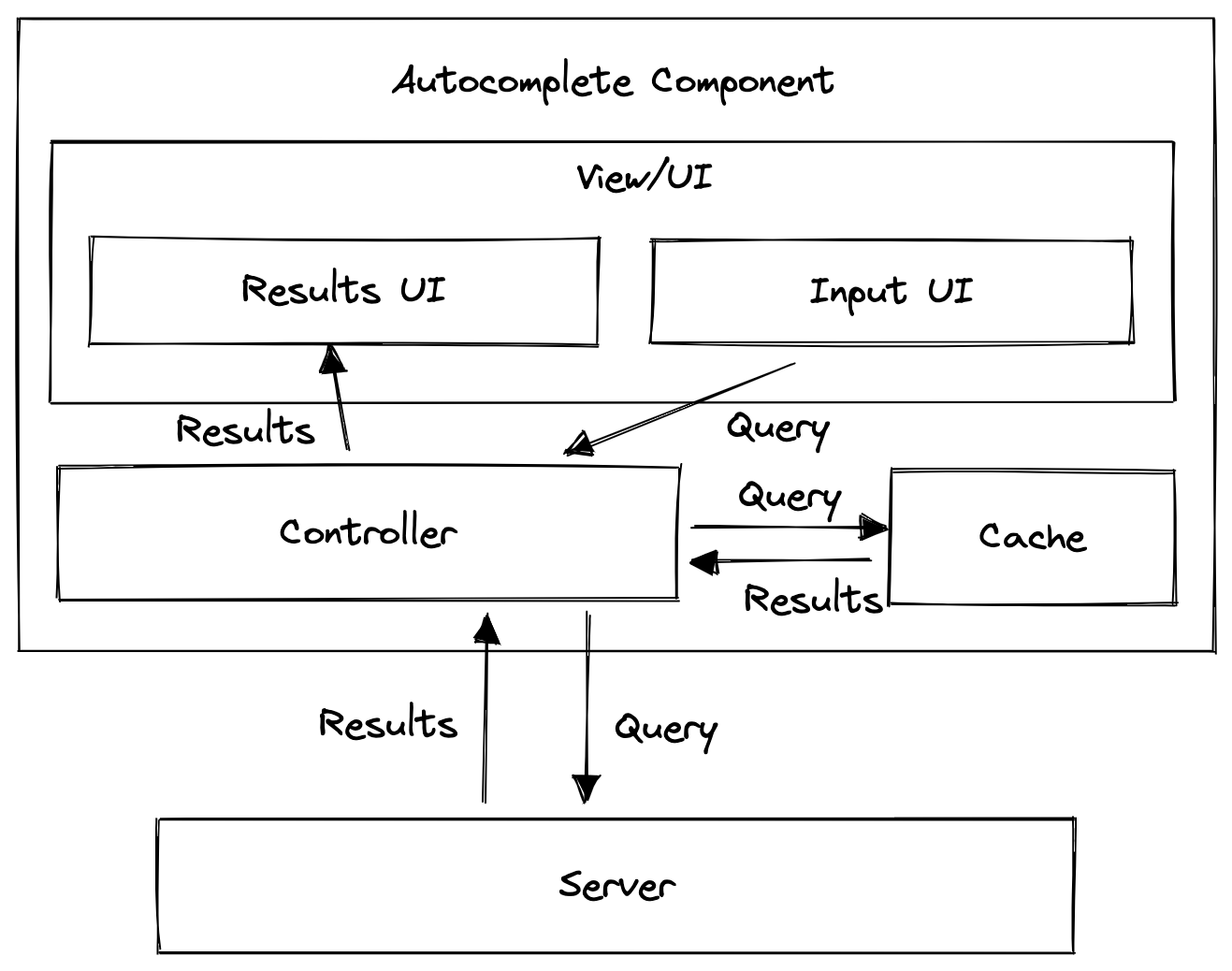
- Input field UI
- Handles user input and passes the user input to the controller.
- Results UI (Popup)
- Receives results from the controller and presents it to the user.
- Handles user selection and informs the controller which input was selected.
- Cache
- Stores the results for previous queries so that the controller can check if sending a request to the server.
- Controller
- The "brain" of the whole component, similar to the Controller in the Model View Controller (MVC) pattern. All the components in the system interact with this component.
- Passes user input and results between components.
- Fetches results from the server if the cache is empty for a particular query.
Data model
- Controller
- Props/options exposed via the component API
- Current search string
- Cache
- Initial results
- Cached results
- Refer to section below for cache data model design
These are only the core fields that are needed for the basic functionality. More fields will be added as we dive deeper into specific topics below.
Interface definition (API)
Since this is a front end system design question, we will focus on the API of the component and only briefly touch on the search API that the server should provide.
Client
Since we want to make a component that is flexible and easy for other developers to use, we cannot make too many assumptions about how the component will be used and have to supply a pretty large amount of options.
Basic API
These are the core APIs which affect the functionality of the component.
- Number of results: The number of results to show in the list of results.
- API URL: The URL to hit when a query is made. For an autocomplete use case, queries are made as the user types.
- Event listeners:
'input','focus','blur','change','select'are some of the common events which developers might want to respond to (possibly log user interactions), so adding hooks for these events would be helpful. - Customized rendering: There are a few ways to allow developers to customize the rendering of the various parts of their UI for their use cases:
- Theming options object: This approach is the easiest to use but the least flexible/customizable. The component can accept an object of key/values (e.g.
{ textSize: 12px, textColor: 'red' }) and use it when rendering. - Classnames: Allow developers to specify their own CSS class names which the component will add to the various UI sub-components.
- Render function/callback: This is an inversion of control technique commonly used in React where the rendering is completely left to the developer. The component invokes a developer-provided function with some data and the developer can customize the logic/code to render the UI based on that data. This is the most flexible approach but requires the most effort from the developer.
- Theming options object: This approach is the easiest to use but the least flexible/customizable. The component can accept an object of key/values (e.g.
Advanced API
These APIs affect the user experience and performance of the component and should be covered if there's enough time.
- Minimum query length: There will likely be too many irrelevant results if the user query is too short as it is not specific enough. We might only want to trigger the search when there's a minimum number of characters typed in, possibly 3 or more.
- Debounce duration: Triggering a back end search API for every keystroke can be quite wasteful, especially when the queries for the first few characters are likely to not be meaningful. Debouncing is a technique that limits the number of time a function gets called. We could debounce hitting of the API so that the server does not get hit too often. With a debounce duration of 300ms, the back end search API will only be called after there has been no user input for 300ms.
- API timeout duration: How long we should be waiting for a response to determine that the search has timed out and we can display an error.
- Cache-related: More details on these options will be covered in the cache section below.
- Initial results
- Results source: network only/network and cache/cache only
- Function to merge results from server and cache
- Cache duration
Server API
The server should provide a HTTP API that supports the following parameters:
query: The actual search querylimit: Number of results in one pagepagination: The page number
pagination and limit are useful if there is a need to allow users to scroll down beyond the initial list of results to get the next "page" of results.
Optimizations and deep dive
With the basics out of the way, we can dive deeper into specific topics which are relevant to the question.
Network
Handling concurrent requests/race conditions
What happens if the user makes changes to the query while there's a pending network request? If there are multiple pending network requests, we will need to be mindful not to display results for a previous search query. We cannot rely on the return order of network responses from the server because an earlier request might only be completed later than a request fired later on.
To know which request's response we should use display, we could:
- Attach a timestamp to each request to determine the latest request and only display the results of the latest request (not the latest response!). Discard the response of irrelevant queries.
- Save the results in an object/map, keyed by the search query string and only present the results corresponding to the input value in the search input.
Which option is better? Given we have a cache that remembers the responses of each search query, option 2 is clearly better. Refer to the cache section details for more details.
It's not advisable to abort requests (via AbortController) or discard responses since the server would have received and processed the request and returned the data back to the client.
Saving the responses for historical keystrokes is useful for cases where users accidentally typed an extra character. "f' -> "fo" -> "foo" -> meant to type "t" but mistyped an extra "r" due to fat fingers -> "foot" -> "footr" -> deletes extra "r" -> "foot" (results for "foot" can be displayed immediately it is already in the cache). If there's debounce, then the requests for "foot" might not have fired immediately and there's no response for "foot" to cache, so this mainly benefits autocomplete components without debounce or people who type slower than the debounce duration.
Failed requests and retries
Server requests can sometimes fail, possibly due to the user's flaky internet connection. The component can automatically retry firing the query. In case the server is indeed offline and we are concerned about overloading the server, we could use an exponential backoff strategy.
Offline usage
If we detect that the device has entirely lost network connection, there's not a whole lot that we can do since our component relies on the server for data. But we could do the following to improve the UX:
- Read purely from cache. Obviously this is not very useful if the cache is empty.
- Not fire any requests so as not to waste CPU cycles.
- Indicate that there's no network connection somewhere in the component.
Cache
What is the cache for? Caches are typically used to improve performance of queries and reducing processing costs by saving the results of previous queries in memory. If/when the user searches for the same term again, instead of hitting the server for the results, we can retrieve the results from memory and instantly show the results, effectively removing the need for any network request and latency.
To provide the best experience, Google and Facebook search inputs cache user queries.
Cache structure
The cache within the component is the most interesting aspect of the component as there are many ways to design the cache, each with its own pros and cons. Explaining the tradeoffs of each is essential to acing front end system design interviews.
1. Hash map with search query as key and results as value. This is the most obvious structure for a cache, mapping the string query to the results. Retrieving the results is super simple and can be obtained in O(1) time just by looking up whether the cache contains the search term as a key.
const cache = {fa: [{ type: 'organization', text: 'Facebook' },{type: 'organization',text: 'FasTrak',subtitle: 'Government office, San Francisco, CA',},{ type: 'text', text: 'face' },],fac: [{ type: 'organization', text: 'Facebook' },{ type: 'text', text: 'face' },{ type: 'text', text: 'facebook messenger' },],face: [{ type: 'organization', text: 'Facebook' },{ type: 'text', text: 'face' },{ type: 'text', text: 'facebook stock' },],faces: [{ type: 'television', text: 'Faces of COVID', subtitle: 'TV program' },{ type: 'musician', text: 'Faces', subtitle: 'Rock band' },{ type: 'television', text: 'Faces of Death', subtitle: 'Film series' },],// ...};
However, see that there are lots of duplicate results especially if we don't do any debouncing as the user is typing and we fire one request per keystroke. This results in the page consuming lots of memory for the cache.
2. List of results. Alternatively, we could save the results as a flat list and do our own filtering on the front end. There will not be much (if any) duplication of results.
const results = [{ type: 'company', text: 'Facebook' },{type: 'organization',text: 'FasTrak',subtitle: 'Government office, San Francisco, CA',},{ type: 'text', text: 'face' },{ type: 'text', text: 'facebook messenger' },{ type: 'text', text: 'facebook stock' },{ type: 'television', text: 'Faces of COVID', subtitle: 'TV program' },{ type: 'musician', text: 'Faces', subtitle: 'Rock band' },{ type: 'television', text: 'Faces of Death', subtitle: 'Film series' },];
However, this is not ideal in practice because we have to do filtering on the client side. This is bad for performance and might end up blocking the UI thread and is especially evident on large data sets and slow devices. The ranking order per result might also be lost, which is not ideal.
3. Normalized map of results. We take inspiration from normalizr and structure the cache like a database, combining the best traits of the earlier approaches - fast lookup and non-duplicated data. Each result entry is one row in the "database" and is identified by a unique ID. The cache simply refers to each item's ID.
// Store results by ID to easily retrieve the data for a specific ID.const results = {1: { id: 1, type: 'organization', text: 'Facebook' },2: {id: 2,type: 'organization',text: 'FasTrak',subtitle: 'Government office, San Francisco, CA',},3: { id: 3, type: 'text', text: 'face' },4: { id: 4, type: 'text', text: 'facebook messenger' },5: { id: 5, type: 'text', text: 'facebook stock' },6: {id: 6,type: 'television',text: 'Faces of COVID',subtitle: 'TV program',},7: { id: 7, type: 'musician', text: 'Faces', subtitle: 'Rock band' },8: {id: 8,type: 'television',text: 'Faces of Death',subtitle: 'Film series',},};const cache = {fa: [1, 2, 3],fac: [1, 3, 4],face: [1, 3, 5],faces: [6, 7, 8],// ...};
There will be pre-processing that needs to be done before showing the results to the user, to map a list's result IDs to the actual result items but the processing cost is negligible if there are only a few items to be shown.
Which structure to use?
Which to use depends on the type of application this component is being used in.
- Short-lived websites: If the component is being used on a page which is short-lived (e.g. Google search), option 1 would be the best. Even though there is duplicated data, the user is unlikely to use search so often that memory usage becomes an issue. The cache is being cleared/reset when the user clicks on a search result anyway.
- Long-lived websites: If this autocomplete component is used on page which is a long-lived single page application (e.g. Facebook website), then option 3 might be viable. However, do also note that caching results for too long might be a bad idea as stale results take up memory without being useful.
Initial results
Noticed how on Google search, when you first focus on the input, a list of results is displayed even though you haven't typed anything yet? Showing an initial relevant list of results could be useful in saving users from typing and reducing server costs.
- Google: Popular search queries today (current affairs, trending celebrities, latest happenings) and historical searches
- Facebook: Historical searches.
- Stock/crypto/currency exchanges: Historical searches or trending stocks
The initial results could be an option on the component and added to the cache where the key is an empty string.
In the past, Facebook loaded a user's friends, pages, groups into the browser cache so that results can be shown instantly via client-side filtering without sending another HTTP request.
Source: The Life of a Typeahead Query
Caching strategy
Caching is a space/time tradeoff where we trade memory space to save on processing time. Having cached results stay around for too long is a bad idea because it consumes memory and if too much time has passed since the cache entry was written, the results are likely irrelevant/outdated. There's little value in using memory to store irrelevant/outdated results.
When to evict the cache depends on the type of application:
- Google: Google search results don't update that often, so the cache is useful and can live for long (hours?).
- Facebook: Facebook search results are updated moderately often, so a cache is useful but entries should be evicted every now and then (half an hour?).
- Stock/currency exchanges: Exchanges with an autocomplete for stock ticker symbols/currency showing the current price in the results might not want to cache at all because the prices change every minute when the markets are open.
We can add the data source/caching strategy and cache duration as configuration options on the component.
- Data source: Whether to read the results from the "network only", "network and cache", "cache only".
- Cache duration/Time-to-live: How long to retain each cache entry for. This will involve adding timestamps to each entry and evicting stale cache entries every now and then.
Performance
Performance here refers to client-side performance since server-side performance (how fast the query returns) is out of scope.
Loading speed
We can't improve how fast the server returns the response, but with client-side caching, we can show results for previous queries near instantly. We can even go one step further and use cached results for future results if there's a match.
Debouncing/throttling
By limiting the number of network requests that can be fired, we reduce server payload and CPU processing.
Memory usage
Long-lived pages might have autocomplete components which accumulate too many results in the cache and hog memory. Purging the cache and freeing up memory is essential for such pages. The purging can be done when the browser is idle or total memory/number of cache entries exceed a certain threshold.
Virtualized lists
If the results contains many items (order of hundreds and thousands), rendering that many DOM nodes in the browser would cost lots of memory and slow down the browser. List virtualization is a technique we can use here to help the component retain its performance at scale.
From https://web.dev:
List virtualization, or "windowing", is the concept of only rendering what is visible to the user. The number of elements that are rendered at first is a very small subset of the entire list and the "window" of visible content moves when the user continues to scroll. This improves both the rendering and scrolling performance of the list.
The trick here is to only render the nodes which are visible and recycle DOM nodes instead of creating new ones. We can make the results window give the illusion that it contains that many results with fake off-screen elements that add up to the height of the non-visible result elements.
User experience
The following are some good UX practices to apply to the autocomplete component:
Autofocus
Add the autofocus attribute to your input if it's a search page (like Google) and you're very certain that the user has a high intention to use the autocomplete when it is present on the screen.
Handle different states
- Loading: Show spinner when there's a background request.
- Error: Show an error message with a retry request button.
- No network: Show an error message that there's no network available.
Handle long strings
Long text in the result items should be handled appropriately, usually via truncating with an ellipsis or wrapping nicely. The text should not overflow and appear outside the component.
Mobile-friendliness
- Each result item should be large enough for user to tap on if used on mobile.
- Dynamic number of results depending on viewport window size, but this is better implemented in userland instead.
- Set helpful attributes for mobile:
autocapitalize="off",autocomplete="off",autocorrect="off",spellcheck="false"so that the browser suggestions do not interfere with the user's search.
Keyboard interaction
- Users should be able to use the component and focus on the autocomplete suggestions just via their keyboard. Read more under the Accessibility section.
- Add a global shortcut key to let the user easily focus on the autocomplete input. A common keyboard shortcut is the / (forward slash) key, which is used by Facebook, X and YouTube.
Typos in search
It is easy to make typographical errors, especially on mobile devices. A fuzzy search is a searching technique where results that matches the search query closely instead of exactly are also considered. Fuzzy searches help you find relevant results even when the search terms are misspelled.
Fuzzy searches can be used if the filtering is purely done on the client side by computing edit distance (e.g. Levenshtein distance) between the search query and the results and selecting the ones with the smallest edit distance. For searches done on the server-side, we can send the query as-is and have the fuzzy matching be done on the server.
Query results positioning
The list of autocomplete suggestions typically appear below the input. However, if the autocomplete component is at the bottom of the window, then there's insufficient space to fully display the results. The suggestions can be made aware of its positioning on the page and render above the input if there's no space to show it below the input.
Accessibility
Screen readers
- Use semantic HTML or use the right
ariaroles if using non-semantic HTML. Use<ul>,<li>for building list items orrole="listbox"androle="option". aria-labelfor the<input>because there usually isn't a visible label.role="combobox"for the<input>.aria-haspopupto indicate that the element can trigger an interactive popup element.aria-expandedto indicate whether the popup element is currently displayed.- Mark the results region with
aria-liveso that when new results are shown, screen reader users are notified. aria-autocompleteto describe the type of autocompletion interaction model the combobox will use when dynamically helping users complete text input, whether suggestions will be shown as a single value inline (aria-autocomplete="inline") or in a collection of values (aria-autocomplete="list")- Google uses
aria-autocomplete="both"while Facebook and X usearia-autocomplete="list".
- Google uses
Keyboard interaction
- Hit enter to perform a search. You can get this behavior for free by wrapping the
<input>in a<form>. - Up/down arrows to navigate the options, wrapping around when the end of the list is reached.
- Escape to dismiss the results popup if it is visible.
- ... and more. Follow the WAI ARIA Combo Box practices.
Comparing Google, Facebook, and X search component
Here's a comparison of Google, Facebook, and X's search autocomplete component and the HTML attributes used.
| HTML Attribute | X | ||
|---|---|---|---|
| HTML Element | <textarea> | <input> | <input> |
Within <form> | Yes | No | Yes |
type | "text" | "search" | "text" |
autocapitalize | "off" | Absent | "sentence" |
autocomplete | "off" | "off" | "off" |
autocorrect | "off" | Absent | "off" |
autofocus | Present | Absent | Present |
placeholder | Absent | "Search Facebook" | "Search" |
role | "combobox" | Absent | "combobox" |
spellcheck | "false" | "false" | "false" |
aria-activedescendant | Present | Absent | Present |
aria-autocomplete | "both" | "list" | "list" |
aria-expanded | Present | Present | Present |
aria-haspopup | "false" | Absent | Absent |
aria-invalid | Absent | "false" | Absent |
aria-label | "Search" | "Search Facebook" | "Search query" |
aria-owns | Present | Absent | Present |
dir | Absent | "ltr"/"rtl" | "auto" |
enterkeyhint | Absent | Absent | "search" |
Note: This table is only accurate at the time of writing since companies update their search components from time to time. The point is to demonstrate is that there's no standardized practice on the ARIA properties to use.
References
Changelog
- 2024/08/21
- Updated Google, Facebook, X's HTML attributes table.
- Changed Twitter to X.
- 2023/01/14
- Update normalized store format to be an object instead of array for quick lookup.